Web scraping has become an essential skill for developers, data scientists, and anyone who needs to gather large amounts of data from the internet efficiently. One tool that stands out in the world of web scraping is Scrapy. This powerful, open-source web crawling framework is designed to make scraping tasks straightforward and effective. In this blog post, we’ll explore what Scrapy is, its key features, how to get started, and some best practices to help you make the most out of this fantastic tool.

What is Scrapy?
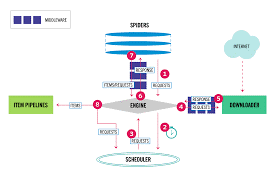
Scrapy is an open-source web scraping framework for Python. It allows you to extract data from websites and process it as needed. Scrapy is highly versatile and can handle a wide range of scraping needs, from simple data extraction tasks to complex, large-scale data collection projects.
Key Features of Scrapy
Scrapy’s popularity stems from its powerful features, which make web scraping more accessible and efficient:
Ease of Use: With Scrapy, you can set up a scraping project quickly, thanks to its user-friendly syntax and well-documented code.
Speed: Scrapy is designed to be fast and efficient. It can handle multiple requests simultaneously, significantly speeding up the scraping process.
Flexibility: Whether you need to scrape a single page or an entire website, Scrapy’s flexible architecture allows you to customize your scraping tasks to fit your specific needs.
Extensibility: Scrapy supports extensions and middlewares, making it easy to add additional functionality as needed.
Data Export: You can easily export the scraped data in various formats, such as JSON, CSV, or XML.
Getting Started with Scrapy
Ready to dive into web scraping with Scrapy? Here’s a step-by-step guide to get you started:
1. Installation
First things first, you need to install Scrapy. It’s straightforward and can be done using pip:
pip install scrapy
2. Creating a New Scrapy Project
Once you have Scrapy installed, you can create a new project. Open your terminal and run:
scrapy startproject myproject
This command will create a new directory with the necessary files and folders for your project.
3. Defining a Spider
Spiders are the core of Scrapy. They define how a website should be scraped, including what data to extract and how to navigate through the pages. Create a new spider by navigating to your project directory and running:
scrapy genspider myspider example.com
This command creates a new spider template in the spiders directory.
4. Writing Your Spider
Open the newly created spider file and start defining your scraping logic. Here’s a simple example to get you started:
import scrapy
class MySpider(scrapy.Spider):
name = “myspider”
start_urls = [
‘http://example.com’,
]
def parse(self, response):
for quote in response.css(‘div.quote’):
yield {
‘text’: quote.css(‘span.text::text’).get(),
‘author’: quote.css(‘span.author::text’).get(),
}
next_page = response.css(‘li.next a::attr(href)’).get()
if next_page is not None:
yield response.follow(next_page, self.parse)
This spider will start at http://example.com, extract quotes and authors from the page, and follow the next page link to continue scraping.
5. Running Your Spider
To run your spider, navigate to your project directory and use the command:
scrapy crawl myspider
Scrapy will start the spider, and you’ll see the extracted data output in your terminal.
Best Practices for Web Scraping with Scrapy
To ensure efficient and ethical web scraping, here are some best practices to follow:
Respect Robots.txt: Always check and respect the website’s robots.txt file to understand the rules regarding web scraping for that site.
Throttle Your Requests: Avoid overloading the server by using Scrapy’s DOWNLOAD_DELAY setting to throttle your requests.
Handle Errors Gracefully: Use Scrapy’s error handling features to manage HTTP errors and retries effectively.
Clean and Validate Data: Always clean and validate your scraped data to ensure it meets your requirements.
Stay Updated: Scrapy is continually evolving. Keep your Scrapy installation updated to benefit from the latest features and security patches.
Conclusion
Scrapy is a powerful tool that can transform your web scraping projects, making them more efficient and manageable. By following the steps outlined above and adhering to best practices, you’ll be well on your way to becoming a web scraping pro. So, why wait? Dive into Scrapy and unlock the potential of web scraping today!
FAQs
1. Is Scrapy suitable for beginners?
Yes, Scrapy is beginner-friendly with extensive documentation and a supportive community, making it a great choice for those new to web scraping.
2. Can Scrapy handle JavaScript-rendered pages?
Scrapy primarily handles static content. For JavaScript-rendered pages, integrating Scrapy with tools like Splash or Selenium is recommended.
3. How do I export data in Scrapy?
Scrapy allows you to export data in various formats like JSON, CSV, and XML using the FEED_FORMAT and FEED_URI settings.
4. Is web scraping legal?
Web scraping legality depends on the website’s terms of service and the intended use of the data. Always check the website’s policies and ensure ethical scraping practices.
5. Can I scrape multiple websites with Scrapy?
Yes, Scrapy can be configured to scrape multiple websites by defining multiple spiders within a single project.
Contact: +971 56 703 4385
Email: info@siliconpioneers.com


